Introduction to NCALab
NCA Model Layout
In general, the forward pass of an NCA follows a threefold process of 1. perception, 2. computing the transition function’s output and 3. interpreting the residual output.
NCALab models are based on the abstract BasicNCAModel class, which defines the NCA model’s structure. BasicNCAModel aggregates three classes that resemble the two main components of NCA inference, namely Perception (neighborhood aggregation filters) and Rule (state transition network), as well as an optional head model for specialized downstream tasks such as classification.
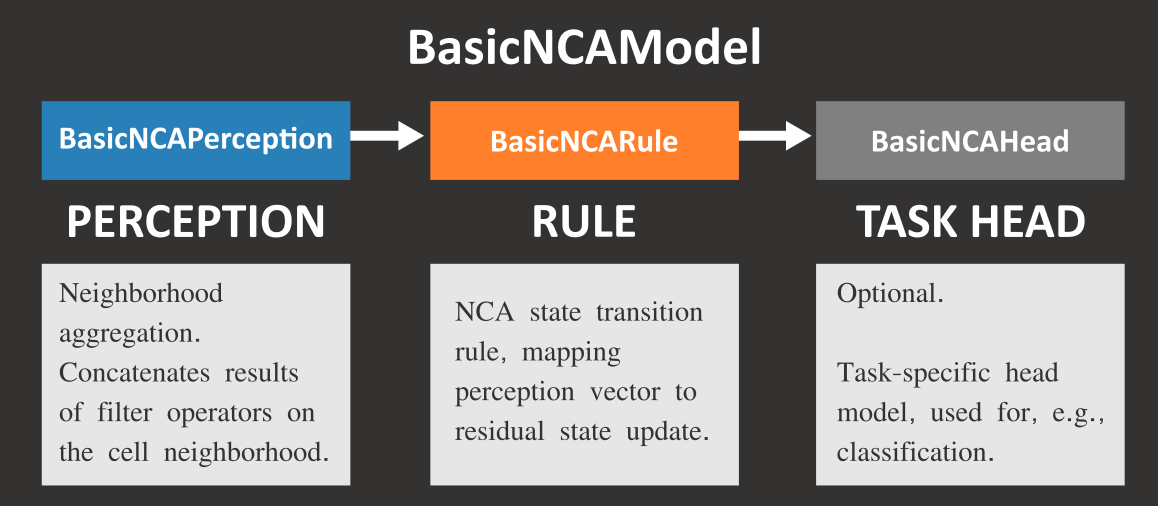
Perception
The first element of an NCA timestep is the neighborhood aggregation, or perception step. In this step, the neighborhood of a cell is observed (perceived) together with the cell’s current state. While in Conway’s Game of Life we would just sum up the number of alive cells in a Moore Neighborhood, a cellular automaton on a grid of continuous values uses a different strategy. In particular, the surrounding cell values are aggregated by using 3x3 filters (larger neighborhoods are also possible). In the original NCA paper by Mordvintsev et al., these filters are sepearable depth-wise convolutions, namely Sobel filters in x- and y-direction. However, these filters can also be learned, which adds some flexibility by allowing us to train an arbitrary number of filters.
The result of an identity filter (i.e. the current cell state itself) is concatenated to the results of the neighborhood aggrating filters, forming a perception vector. All perception vectors of all cells in all images of the batch form a perception tensor which is passed as input to the transition rule.
Transition Rule
Typically, the cell state transition rule of an NCA is simply a two-layer Multi-Layer Perceptron (MLP),
which receives the perception vector of the previous step and outputs the residual cell update.
Using a ReLU activation between layers has so far been the most successful strategy.
Since this recipe works well for many tasks, BasicNCARule is not abstract and can be used as-is.
However, if you’re interested in tweaking the rule by using a different type of model, here are some useful hints to follow.
1. Perception vectors and residual updates are expected to be BCWH, meaning that the four dimensions
of input/output tensors are expected to be ordered Batch, Channels, Width and Height.
2. The model is expected to be named network, as is the case in the BasicNCARule implementation.
Task Head
Task head models should subclass the BasicNCAHead class – you can take a look at ClassificationNCAHead
to get an understanding of how this class is supposed to work.
For tasks that do not require a separate head, the head attribute of BasicNCAModel is simply None.
Subclasses of abstract BasicNCAHead need to implement the following methods:
forward(), takes result of Rule network and computes the final prediction.freeze(), freezes the layers of the head model.
Subclassing BasicNCAModel
Subclasses of BasicNCAModel need to implement the following methods:
loss(), which computes a single loss term and may compute multiple subterms.metrics(), which is optional but highly recommended for computing evaluation metrics.
Transfer Learning
NCA models can be frozen during training, either completely or partially, by calling the freeze() method.
This method takes care of calling freeze() in both the Rule and Head modules.
The Perception module is frozen as well, if learned filters are being used.
If the freeze_last parameter is set to False (default), the final, linear layer is kept trainable,
which is useful for transfer-learning experiments.